这篇文章好棒!Alphago进化史 漫画告诉你Zero为什么这么牛
来源:环球科学ScientificAmerican公众号



那么AlphaGo Zero与AlphaGo(用AlphaGo表示以前的版本)都有哪些主要的差别呢?
1。在训练中不再依靠人类棋谱。AlphaGo在训练中,先用人类棋谱进行训练,然后再通过自我互博的方法自我提高。而AlphaGo Zero直接就采用自我互博的方式进行学习,在蒙特卡洛树搜索的框架下,一点点提高自己的水平。
2。不再使用人工设计的特征作为输入。在AlphaGo中,输入的是经过人工设计的特征,每个落子位置,根据该点及其周围的棋的类型(黑棋、白棋、空白等)组成不同的输入模式。而AlphaGo Zero则直接把棋盘上的黑白棋作为输入。这一点得益于后边介绍的神经网络结构的变化,使得神经网络层数更深,提取特征的能力更强。
3。将策略网络和价值网络合二为一。在AlphaGo中,使用的策略网络和价值网络是分开训练的,但是两个网络的大部分结构是一样的,只是输出不同。在AlphaGo Zero中将这两个网络合并为一个,从输入到中间几层是共用的,只是后边几层到输出层是分开的。并在损失函数中同时考虑了策略和价值两个部分。这样训练起来应该 会更快吧?
4。网络结构采用残差网络,网络深度更深。AlphaGo Zero在特征提取层采用了多个残差模块,每个模块包含2个卷积层,比之前用了12个卷积层的AlphaGo深度明显增加,从而可以实现更好的特征提取。
5。不再使用随机模拟。在AlphaGo中,在蒙特卡洛树搜索的过程中,要采用随机模拟的方法计算棋局的胜率,而在AlphaGo Zero中不再使用随机模拟的方法,完全依靠神经网络的结果代替随机模拟。这应该完全得益于价值网络估值的准确性,也有效加快了搜索速度。
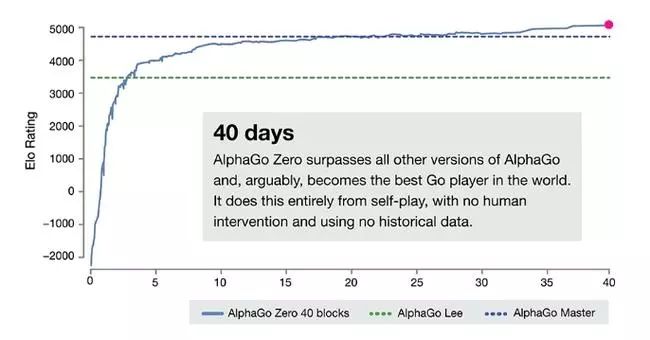
6。只用了4块TPU训练72小时就可以战胜与李世石交手的AlphaGo。训练40天后可以战胜与柯洁交手的AlphaGo。
3,809 total views, 2 views today