「尽信AI,不如无AI」丶「役AI ,而不役於AI」
Deepmind 刊登在Nature 的关键论文「Mastering the game of Go with deep neural networks and tree search」叙述了Alphago 的运作原理;不久,Deepmind 又在Nature 上发表了「Mastering the game of Go without human knowledge」一文,展示他们更为强大的新版围棋程式AlphaGo Zero,验证了即便在像围棋这样最具挑战性的博弈领域,也可以通过纯粹的和自己对弈之方式来达到自我完善的目的。
目前,AI 的思维方式乃使用了蒙地卡罗搜寻,结合两个深度学习神经网络。据开发公司称:其既可结合树状图的长远推算,又可像「人类大脑」一样自发地学习,进行「直觉」训练并培养「价值判断」,提高围棋实力。是否真的如此?以下简单说明:
蒙地卡罗搜寻法 (Monte Carlo Tree Search, MCTS) 用以下四个动作进行搜寻的工作:
1. 选择 (Selection):即随机选择一个子选点。
2. 扩充 (Expansion):在前述子选点下,再创建一个子子选点。
3. 模拟 (Simulation):以前述的子子选点为基础,进行一场模拟的博弈,称为一个rollout。
4. 逆向传播 (Backpropagation):将博弈的结果传输回去,建立激励的反馈,并以此更新权重。
以养鱼来比喻。假设池子里有许多鱼苗,我们的目的是培育出可以出国比赛拿金牌的冠军鱼。鱼饲料是我们可以运用的工具:先随便乱撒一些鱼饲料,看哪些鱼会来吃,这叫做「选择」;等到有几只来吃了,再喂它们多吃一粒,这叫做「扩充」;之後观察其表现,看哪几只比较朝气蓬勃,游得活蹦乱跳的,叫做「模拟」;表现好的,就记住其样貌长相,等到下一次喂食时,就把鱼饲料集中喂给这几只,叫做「逆向传播」。当然,前述的搜寻程序还是继续进行,如果在随机撒鱼饲料的过程中,又发现了新的可造之材,那麽重心就会移转到这些具有冠军潜力的鱼苗上面,除非此种情况发生,否则一开始发掘的几只鱼苗还是会持续地培育下去,把它们愈养愈大。
AlphaGo 的成功关键在於策略网络 (Policy Network) 和价值网络 (Value Network) 系统的建立。策略网络可以说是在输入人类棋谱後,产生类似人类第一感应该下在哪里的「直觉」;而价值网络则是在大量的自我对弈後所得到的评估数值之「判断」。
新一代的AlphaGo Zero 援用了一个多输出的类神经网络,来同时估计策略函数和价值函数两者。此外,不同的是,AlphaGo Zero 策略函数的训练方式,旨在减少类神经网络与MCTS 搜寻结果之间的差距,称为regression;而AlphaGo 原本所使用的,以输入人类棋谱方式,所建立的reinforce 演算法,则叫做policy gradient。简单地说,AlphaGo Zero 是利用大量的自我对弈,同时产生应该下在哪里的「直觉」和评估数值之「判断」,不但比原本的演算法更为简单直截,而且没有受到人类思维的「污染」。
如上所述,AI 的思维方式,是从第一手到最後一手,以胜率极大化 (即所谓minmax) 为指导,把它认为最佳的着手,一手一手「顺向」地发展下去;我们将其称为「养对法」,正如同前面养鱼的比喻。
比方说,树枝图里的第一层有某个潜在选点,可以让胜率更好,它就会开始放权重下去计算,如果真的推翻了前面假定的最佳变化图,它就会把这个选点往下一层发展,看看在里面有没有潜在选点⋯,这样一层一层地往下推进,最後找到最佳的变化图。从第一手开始,AI 就已经有一个胜率的判断在那里指导,这是人类做不到的,人类必需计算到相当的程度,有了一定的「形状」之後,才能够进行「价值判断」。
而人类的思维方式,则是从最後一手到第一手,把他/她认为错误的着手剔除,这样一手一手「逆向」地回溯,进行「逆向归纳」(即所谓 backward induction),我们称之为「沥错法」。相较於AI 的思维,方向是相反的。
让我们用一个简单的二手诘棋来说明:
命题是「黑先杀白」。所以,对黑而言,正解必须「完封」白的所有抵抗;而白只要找到一条生路,就算是成功。
现在棋盘上有三个「空」,代表黑有A丶B丶C 三个选点,白有X丶Y 二个选点。其中,英文代码只是顺序,而不是位置;位置是可以重复的,比方说,黑先选A,白剩下X丶Y 可以选择,现在黑再选B 时,黑B 可以是原先白X 的位置。
假设随机选择的路径,结果是「AX活」,黑因不能「完封」对手,所以失败,要更换选点;假设重新选择的路径,结果是「BX死」,但不代表这就是正解,因为如果存有「BY活」,黑仍失败,还是要更换选点;最後,黑必须兼有「CX死」和「CY死」,也就是要能够「完封」对手的所有抵抗,才算是正解。在前述逆向推理之过程中,A丶B 的错误着手被黑「沥掉」了。
让我们将推理放宽到三层:白有1丶2丶3丶4 四个选点,黑有A丶B丶C 三个选点,白有X丶Y 二个选点。基於白1,如果黑存有兼有「CX死」和「CY死」这样的可能性,代表白因不能「完封」对手而失败,为什麽呢?因为白下1 时,黑只要下C,就可以置白於死地了,所以白1 是错误的选点,要被白「沥掉」。白2 若是局部的最佳着手,其前提是:要能够「完封」对手可以「完封」自己的所有可能。
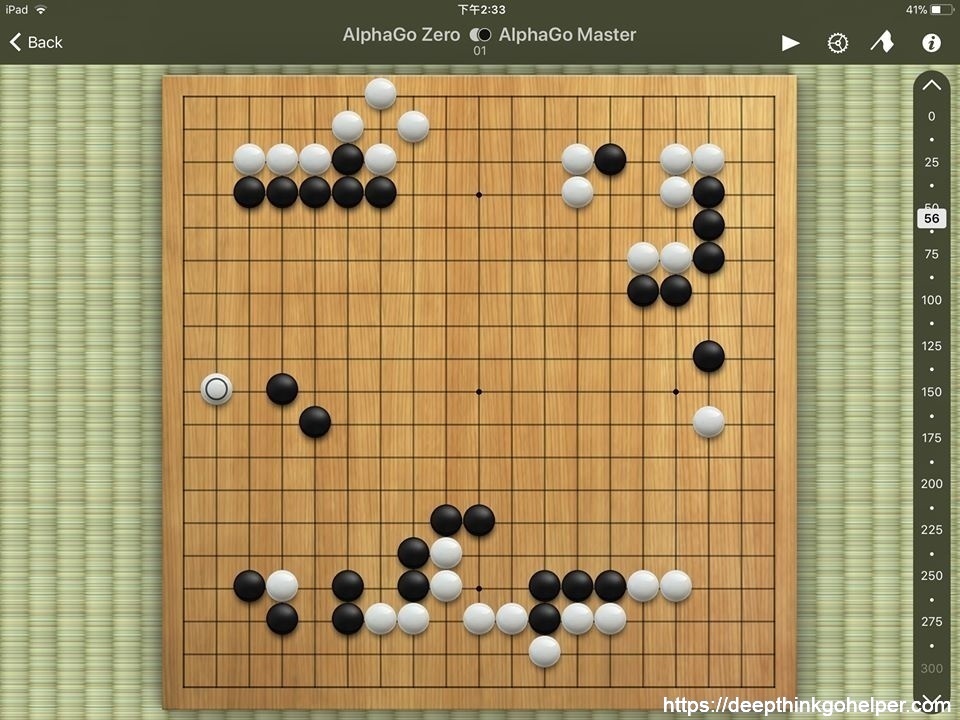
以下纪录AI 分析Alphago Master 对Alphago Zero 第一局的资料内容,我不加个人的诠释和人工的删枝剪叶,纯粹将分析的结果描述出来。其中,第一名的playout 比第二名少很多,是因为现在第二名的「鱼」原先一直保持在第一名的位置,所以AI 给它吃了很多的「鱼饲料」,一直到playout 50万左右,原先第二名的「鱼」却突然超前成为第一名,这时候AI 才惊觉到,它有可能是真正的「冠军鱼」,故进而喂了很多饲料给它;也许再继续跑下去,它的计算量会比原来的第一名还要多也不一定,但因这篇贴文的目的主要是在陈述AI 的思维过程,而非在於真正「定格」後的计算结果,所以就此打住。
理论上,即便是蒙地卡罗搜寻,因AI 的计算量无限,而棋盘的大小有限,所以搜寻与探索可以穷尽所有的变化。围棋是有正解的,纯就理论而言。而这也正是Turing 的停机问题 (Halting Problem) 之另一种表述。
但因人的生命和时间有限,除非别人把他花了很长时间,所得到尽可能趋近正解的答案,在一秒钟之内像剥好皮的荔枝塞进你的嘴巴,否则,答案要达到多「正确」,永远系於你花了多少的时间在上面。所以,正解的「相对性」,就变成了一个成本效益的问题。
借助AI,就像人有了车,可以以比步行快很多的速度,到达步行难以企及的地方。海岛国家的我们或许没有这个经验,但在大陆国家,往往要到一个地方,即便是开车,路程也是以天计的。那麽,要让AI 跑到什麽程度,才可以大致上称为「有结论」呢?让我们用「定格」这个词来描述:所谓定格,就是不管再怎麽计算,这个变化图都不会再更动了,後面的计算,就像是球赛的垃圾时间一样,不会再改变结果了,只是让时间跑下去而已。
假设一手棋有五种可能的应法,每一个应法分别需要AI 跑多少playout 才能够「定格」呢?在这里先卖一个关子。把这五种应法所需要的计算量加总起来,就是一手棋要得到初步结论所需要的总计算量了。但,在这五种应法之外,谁又知道会不会有什麽奇想天外的妙手呢?
成本效益创造了商机。如果人们都不用花力气,让AI 来帮人类开车丶做事,那该有多好啊?新创事业主和投资金主已经在勾勒这美丽的图像了。让AI 全面接手许多人类的工作,是否可依赖呢?难道没有「神之一手」的漏洞存在吗?
李世石两度下到AI 的盲点,让旁边埋伏的「僵尸」纷纷复活,最终以彷佛看到AI 砰然倒下的戏剧性结果赢得比赛,被称为「神之一手」,造成话题。但究其成功,并非因为棋局的内容如吴清源对秀哉的三三星天元之一局那麽复杂,而是因为AI 对於旁边埋伏的「隐形僵尸」茫然无察丶或者「不屑一顾」所致。这两个「神之一手」在局部的复杂性,应该是业馀高段可以算得出来的程度,但AI 的「直觉」却把它给漏掉了。
本局因为Alphago Master 和Alphago Zero 是兄弟,弟弟没看到的哥哥也不会看到,所以不会有「神之一手」的情况发生。计算的深度系於主机和时间,在本局当然是惊人的。有人说:因为AI 可以让职业高手二至三颗子,所以它的答案之「正确」程度也同理高於人类二至三子。这推论正确吗?如果能让二至三子,是除了计算的正确性外,另有其他的原因,那麽前述推理就不充分了。总之,「尽信AI,不如无AI」丶「役AI ,而不役於AI」,应是对AI 的优缺点有所理解後所持的态度吧。
FACEBOOK网友 蔡讲讲分享
7,927 total views, 2 views today